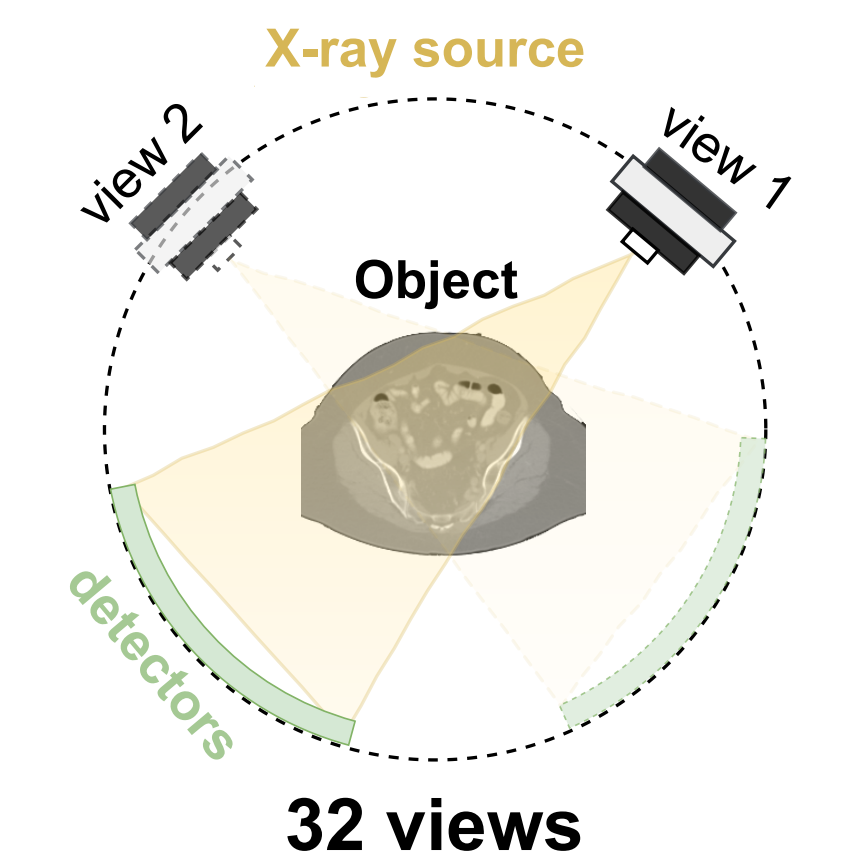
Inverse problems span across diverse fields. In medical contexts, computed tomography (CT) plays a crucial role in reconstructing a patient's internal structure, presenting challenges due to artifacts caused by inherently ill-posed inverse problems. Previous research advanced image quality via post-processing and deep unrolling algorithms but faces challenges, such as extended convergence times with ultra-sparse data. Despite enhancements, resulting images often show significant artifacts, limiting their effectiveness for real-world diagnostic applications. We aim to explore deep second-order unrolling algorithms for solving imaging inverse problems, emphasizing their faster convergence and lower time complexity compared to common first-order methods like gradient descent. In this paper, we introduce QN-Mixer, an algorithm based on the quasi-Newton approach. We use learned parameters through the BFGS algorithm and introduce Incept-Mixer, an efficient neural architecture that serves as a non-local regularization term, capturing long-range dependencies within images. To address the computational demands typically associated with quasi-Newton algorithms that require full Hessian matrix computations, we present a memory-efficient alternative. Our approach intelligently downsamples gradient information, significantly reducing computational requirements while maintaining performance. The approach is validated through experiments on the sparse-view CT problem, involving various datasets and scanning protocols, and is compared with post-processing and deep unrolling state-of-the-art approaches. Our method outperforms existing approaches and achieves state-of-the-art performance in terms of SSIM and PSNR, all while reducing the number of unrolling iterations required.
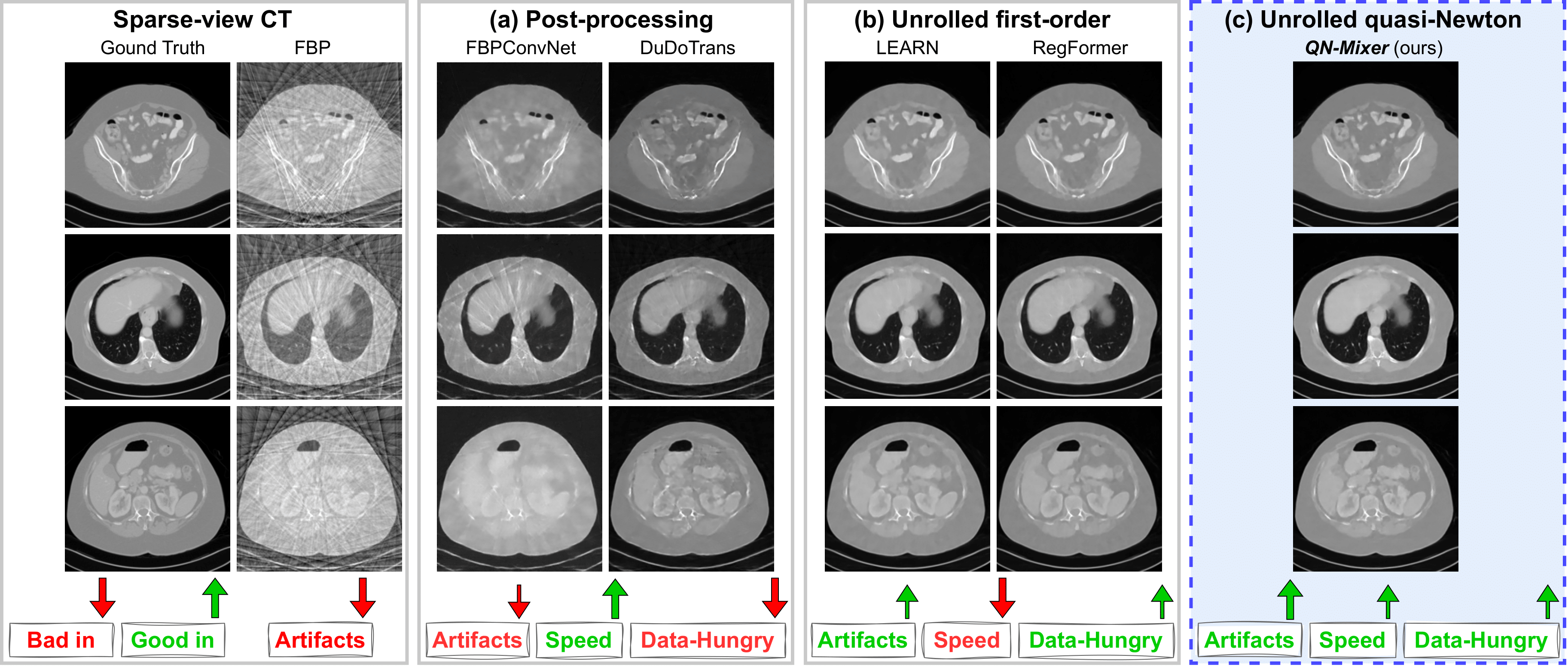
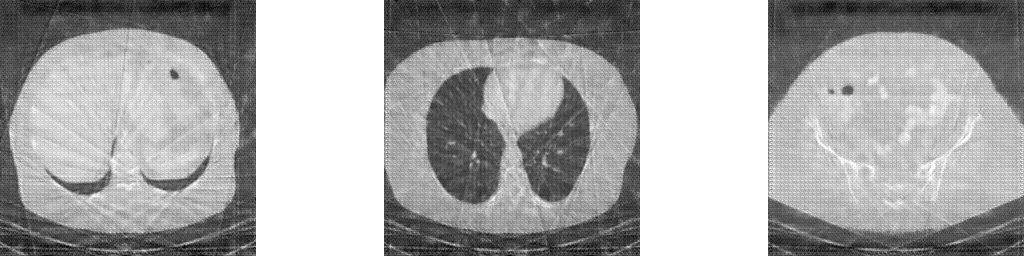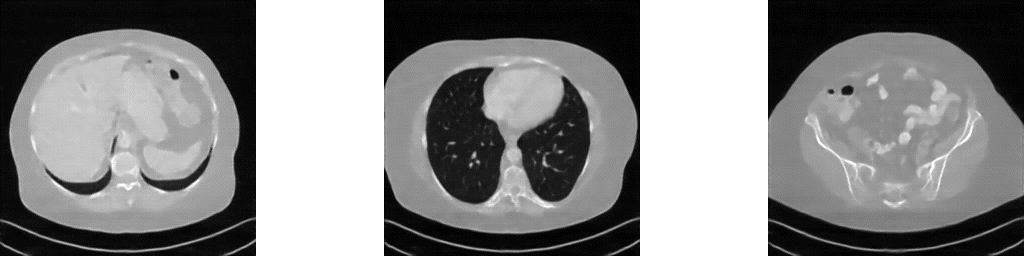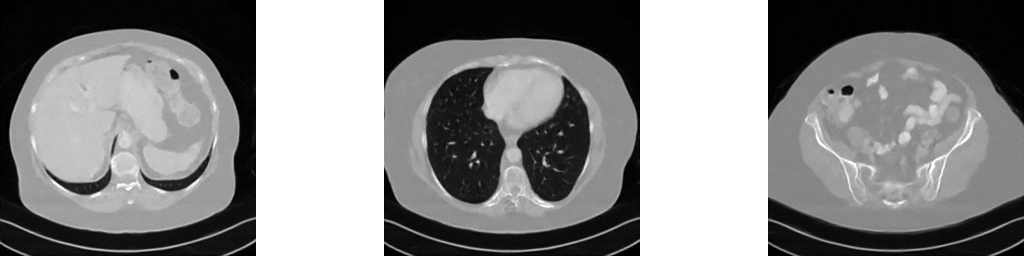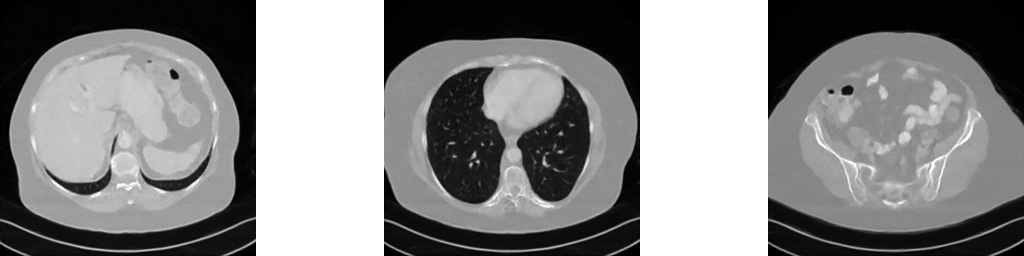
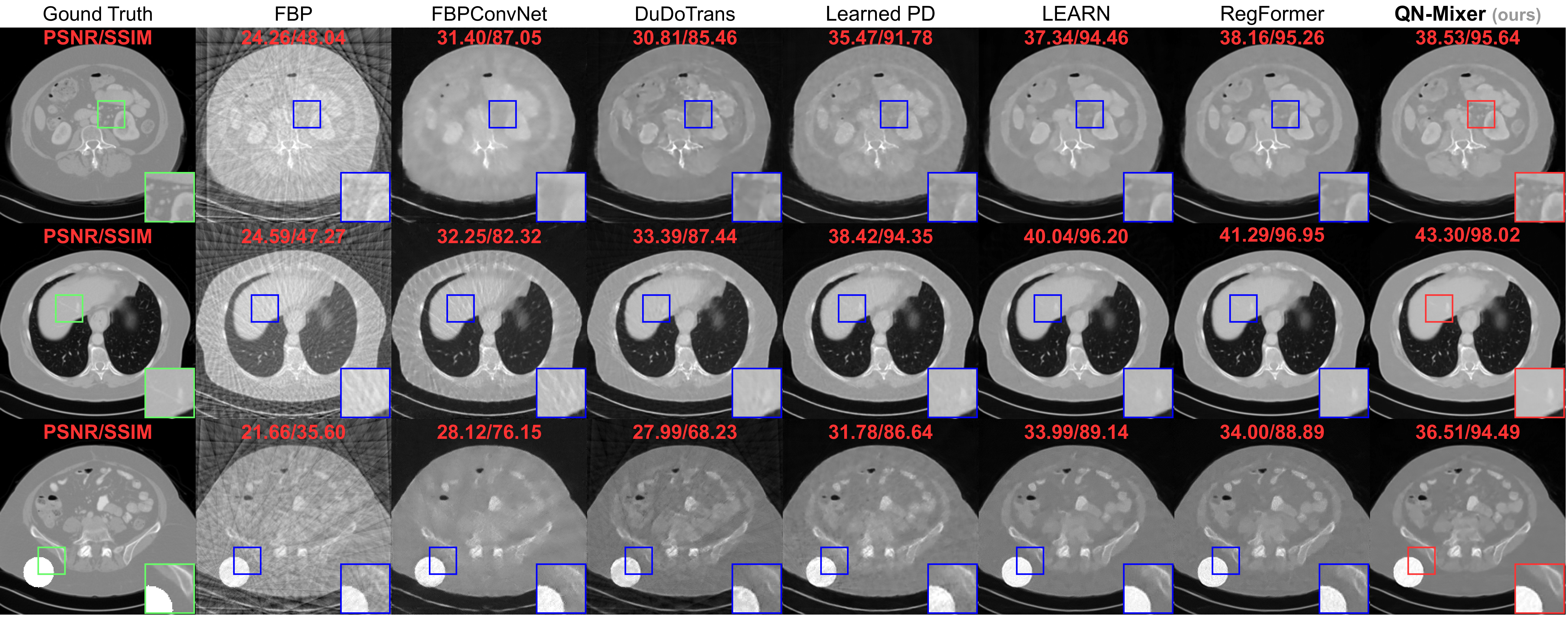
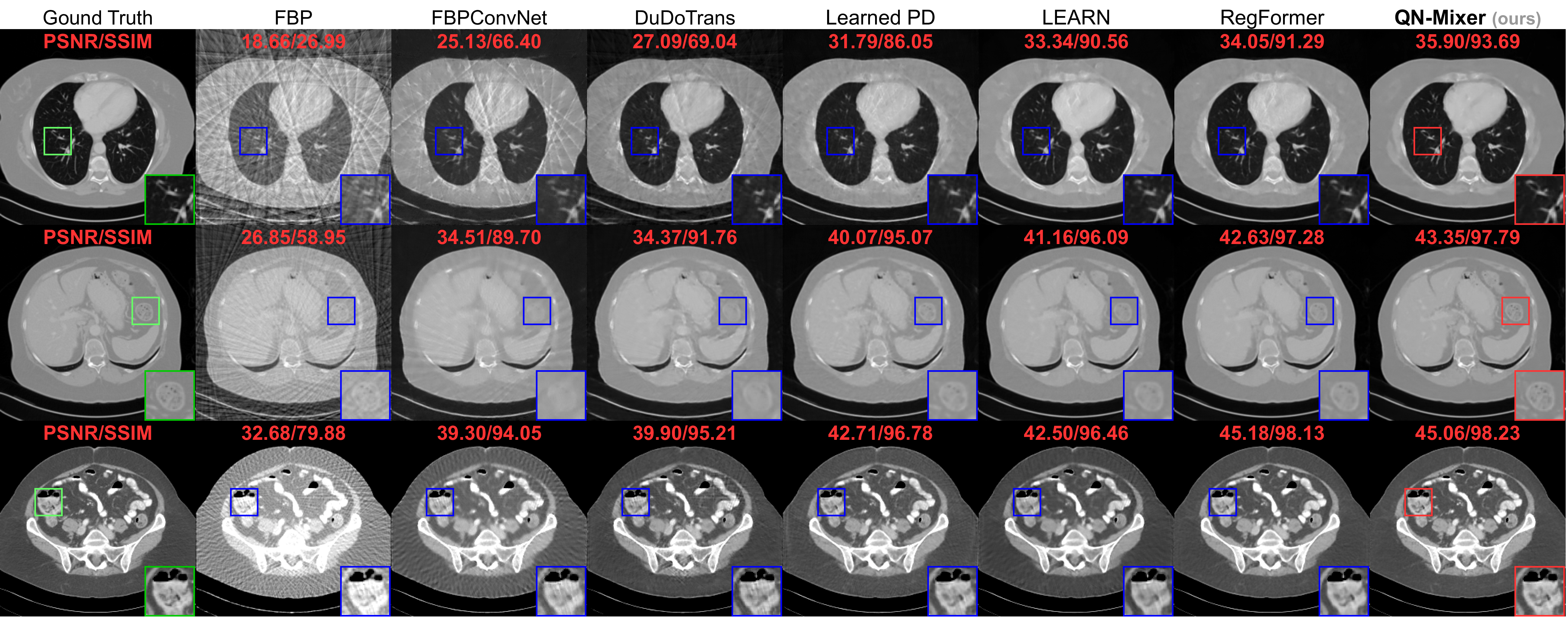
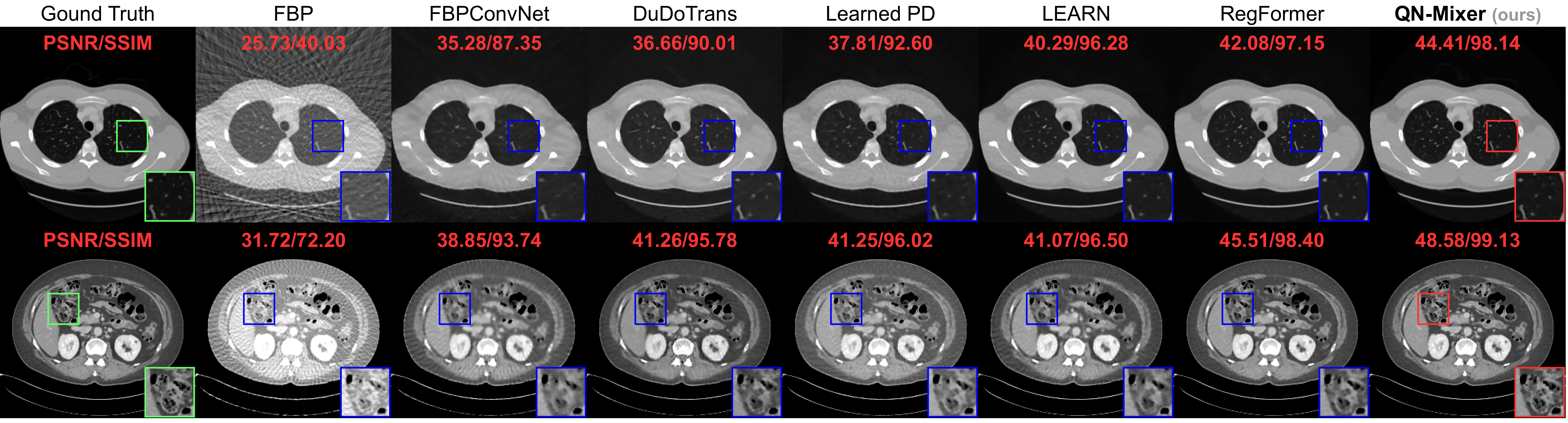
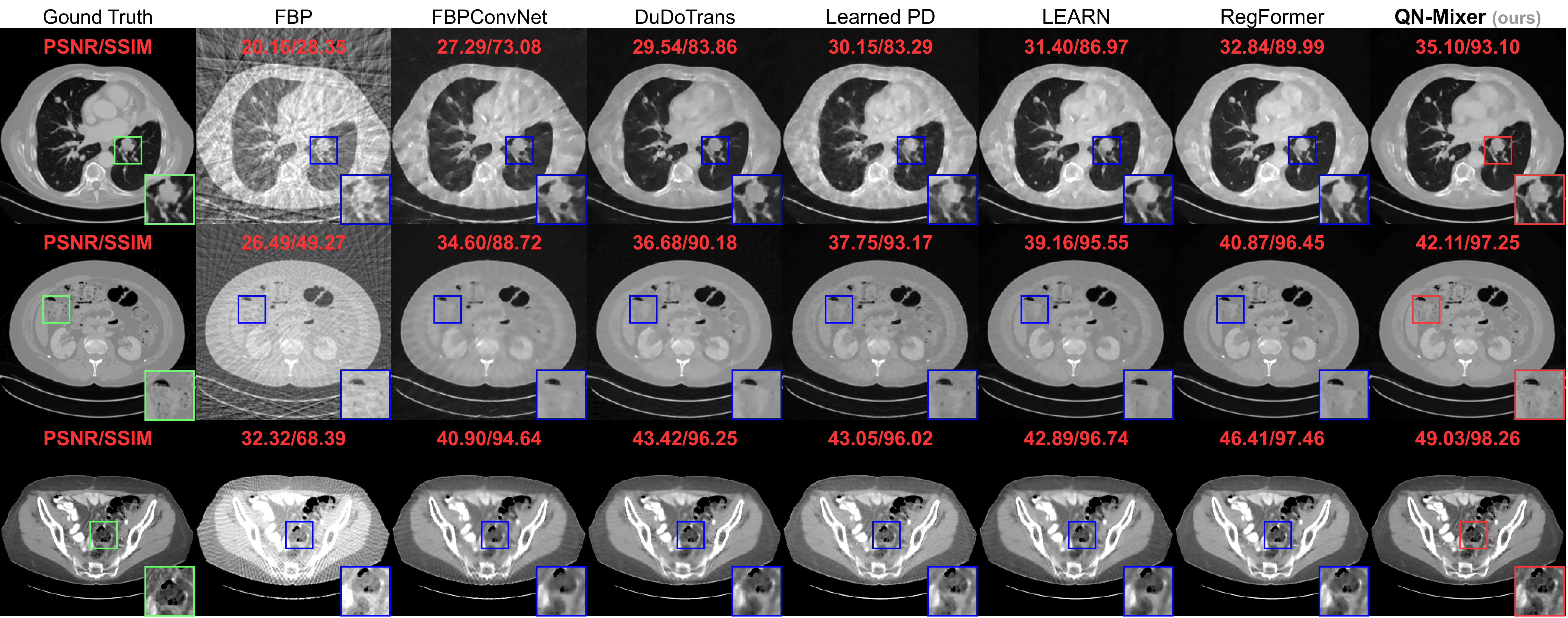
Reconstructed images using the well-known Filtered Back Projection (FBP) algorithm suffer from pronounced streaking artifacts.
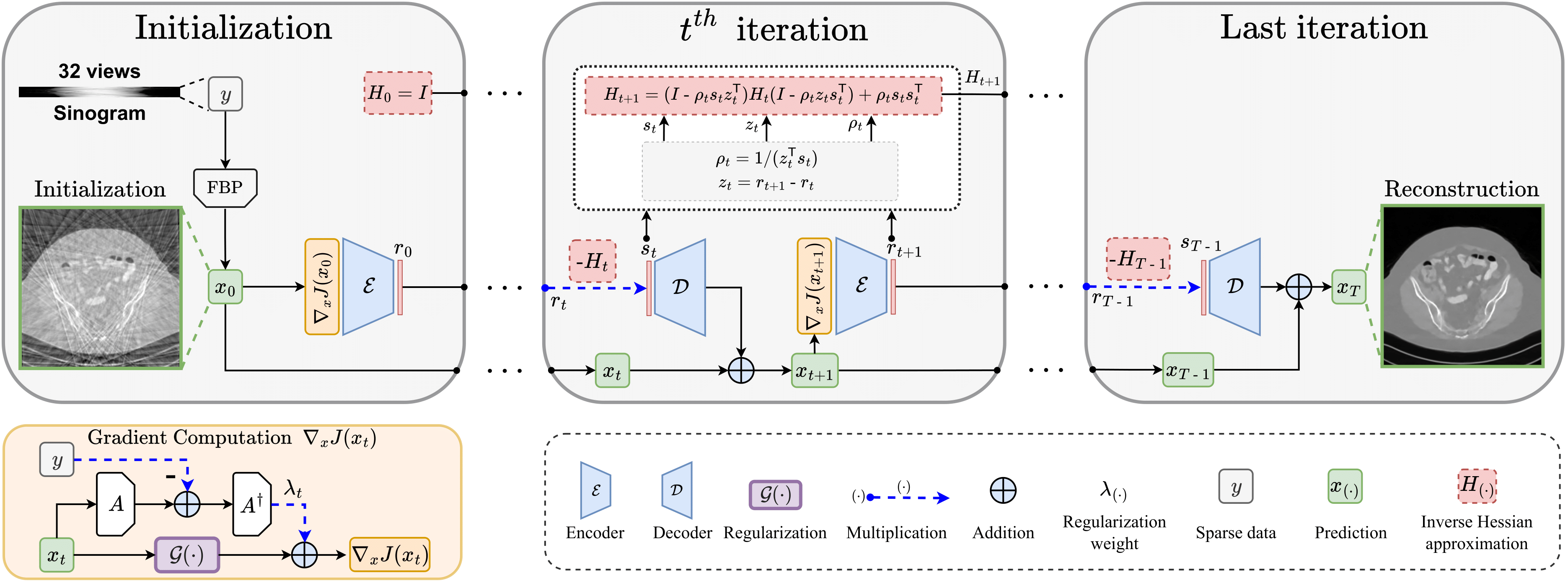
Our method is a new type of unrolling networks, drawing inspiration from the quasi-Newton method. The figure above illustrates the QN-Mixer architecture. It approximates the inverse Hessian matrix using a latent BFGS algorithm and incorporates a non-local regularization term, Incept-Mixer, aimed at capturing non-local relationships. To address the computational challenges associated with full inverse Hessian matrix approximation, a latent BFGS algorithm is utilized.
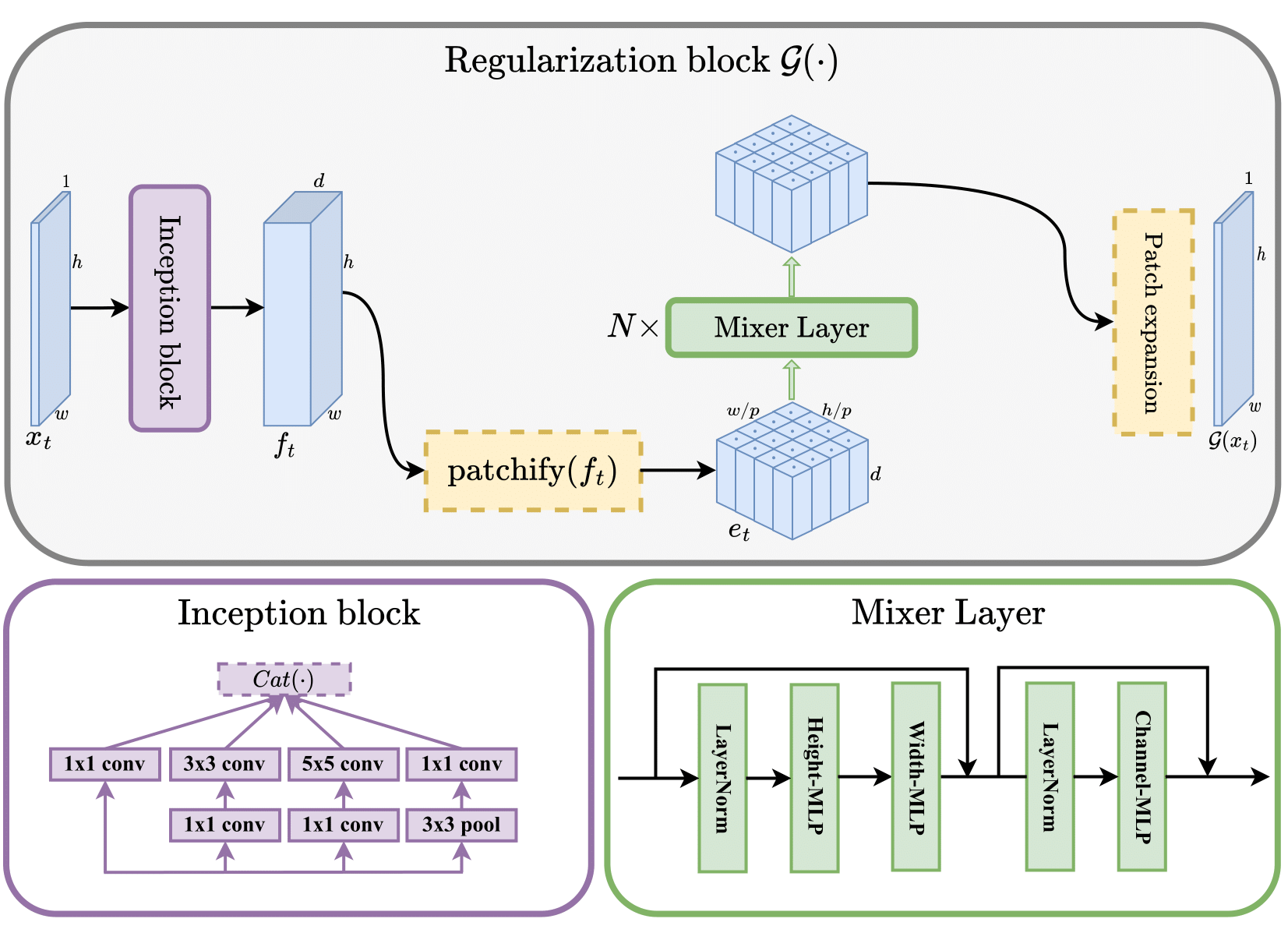
Incept-Mixer bloc is crafted by drawing inspiration from both the multi-layer perceptron mixer and the inception architecture, leveraging the strengths of each: capturing long-range interactions through the attention-like mechanism of MLP-Mixer and extracting local invariant features from the inception block.
@inproceedings{ayad2024,
title={QN-Mixer: A Quasi-Newton MLP-Mixer Model for Sparse-View CT Reconstruction},
author={Ayad, Ishak and Larue, Nicolas and Nguyen, Maï K.},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024},
}
This work was granted access to the HPC resources of IDRIS under the allocation 2021-[AD011012741] / 2022-[AD011013915] provided by GENCI and supported by DIM Math Innov funding.